递归(包括循环)与Scheme的算术基本过程结合可以实现各种数值计算技术。作为一个例子,我们来实现辛普森法则,这是一个用来计算定积分的数值解的过程。
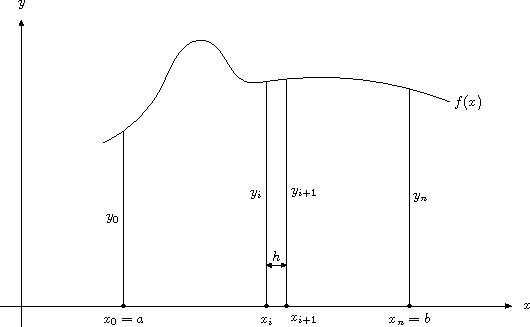
函数f(x)在区间[a,b]上的定积分可以看作是f(x)曲线下方从x=a到x=b的区域的面积。也就是说,我们把f(x)的曲线绘制在xy平面上,然后找到由该曲线,x轴,x=a和x=b所围成区域的面积即是积分值。
根据辛普森法则,我们把积分区间[a,b]划分为n个相等的区间,n是一个偶数(n越大,近似的效果就越好)。区间边界在x轴上形成了n+1个点,即:$x_0, x_1, \ldots, x_i, x_{i+1}, \ldots, x_n$ ,其中 $x_0=a, x_n=b$ 。每个小区间的长度是h=(b-a)/n,这样 $x_i=a+i_h$ ,我们然后计算f(x)在区间端点的纵坐标值,即,其中 $y_i=f(x_i)=f(x+i_h)$。辛普森法则用下列算式模拟f(x)在a到b之间的定积分1:
$$\frac{h}{3}[(y_0+y_n)+4(y_1+y_3+\dots +y_{n-1})+2(y_2+y_4+\dots +y_{n-2})]$$
我们定义一个过程integrate-simpson,该过程接受四个参数:积分函数f,积分限a和b,以及划分区间的数目n。
(define integrate-simpson
(lambda (f a b n)
;...
首先我们需要在integrate-simpson函数里做的是保证n为偶数,如果不是的话,我们直接把n加上1.
;...
(unless (even? n) (set! n (+ n 1)))
;...
接下来我们把区间长度保存在变量h中。我们引入两个变量h*2和n/2来保存h的两倍和n的一半,因为我们会在后面的计算过程中经常用到这两个变量。
;...
(let* ((h (/ (- b a) n))
(h*2 (* h 2))
(n/2 (/ n 2))
;...
我们注意到 $y_1 + y_3 + \cdots + y_{n−1}$ 与 $y_2 + y_4 + \cdots + y_{n−2}$ 都要把每个纵坐标进行相加。所以我们定义一个本地过程sum-every-other-ordinate-starting-from来捕获公共的循环过程。通过把这个循环抽象为一个过程,我们可以避免重复写这个循环。这样不仅减少了劳动量,而且减少了错误发生的可能,因为我们只需要调试一个地方即可。
过程sum-every-other-ordinate-starting-from接受两个参数:起始纵坐标和被相加的纵坐标的数量。
;...
(sum-every-other-ordinate-starting-from
(lambda (x0 num-ordinates)
(let loop ((x x0) (i 0) (r 0))
(if (>= i num-ordinates) r
(loop (+ x h*2)
(+ i 1)
(+ r (f x)))))))
;...
我们现在可以计算着三个纵坐标的和,然后把它们拼起来得到最后的结果。注意 $y_1+y_3+ \cdots + y_{n−1}$中有n/2项,在 $y_2 + y_4 + \cdots + y_{n−2}$ 中有(n/2)-1项。
;...
(y0+yn (+ (f a) (f b)))
(y1+y3+...+y.n-1
(sum-every-other-ordinate-starting-from
(+ a h) n/2))
(y2+y4+...+y.n-2
(sum-every-other-ordinate-starting-from
(+ a h*2) (- n/2 1))))
(* 1/3 h
(+ y0+yn
(* 4.0 y1+y3+...+y.n-1)
(* 2.0 y2+y4+...+y.n-2))))))
现在我们来用integrate-simpson来求下面函数的定积分:
$$\phi(x) = \frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}$$
我们首先需要用Scheme的S表达式来定义 $\phi$ 2。
(define *pi* (* 4 (atan 1)))
(define phi
(lambda (x)
(* (/ 1 (sqrt (* 2 *pi*)))
(exp (- (* 1/2 (* x x)))))))
注意我们用 $tan^{-1}1 = \frac{\pi}{4}$ 来定义*pi*3。
下面的调用分别计算了从0到1,2,3的积分值。都使用了10个区间。
(integrate-simpson phi 0 1 10)
(integrate-simpson phi 0 2 10)
(integrate-simpson phi 0 3 10)
如果精确到小数点后四位,上面的值应该分别是0.3413 0.4772 0.4987。可以看出我们实现的辛普森积分法确实获得了相当精确的值!4
每次都指定区间数目感觉不是很方便。对某个积分来说足够好的n可能对另一个积分来说差太多。这种情况下,最好指定一个可以接受的误差e,然后让程序计算到底需要分多少个区间。完成该任务的典型方法是让程序通过增加n来得到更好的结果,直到连续两次结果之间的误差小于e。因此:
(define integrate-adaptive-simpson-first-try
(lambda (f a b e)
(let loop ((n 4)
(iprev (integrate-simpson f a b 2)))
(let ((icurr (integrate-simpson f a b n)))
(if (<= (abs (- icurr iprev)) e)
icurr
(loop (+ n 2)))))))
这里我们连续两次计算辛普森积分(用我们最初定义的过程integrate-simpson),n从2,4,。。。注意n必须是偶数。当当前n的积分值icurr与前一次n的积分值iprev的差小于e时,我们返回icurr。
这种方法的问题是我们没有考虑对于某个函数来说可能只有某一段或多段能从增长的区间中获益。而对于函数的其他段而言,区间增长只会增加计算量,而不会让整体的结果更好。对于一个增长的适应过程而言,我们可以把积分拆成相邻的几段,让每段的精度独立的增长。
(define integrate-adaptive-simpson-second-try
(lambda (f a b e)
(let integrate-segment ((a a) (b b) (e e))
(let ((i2 (integrate-simpson f a b 2))
(i4 (integrate-simpson f a b 4)))
(if (<= (abs (- i2 i4)) e)
i4
(let ((c (/ (+ a b) 2))
(e (/ e 2)))
(+ (integrate-segment a c e)
(integrate-segment c b e))))))))
初始段是从a到b,为了找到一段的积分,我们用两个最小的区间数目2和4来计算辛普森积分i2和i4。如果误差在e以内,就返回i4。如果没有的话我们就把区间分成两份,递归计算每段的积分并相加。通常,同一层的不同段以它们自己的节奏来汇聚。注意当我们积分半段时,允许的误差也要减半,这样才不会产生精度丢失。
这个过程中仍然存在一些低效之处:积分i4重新计算了计算i2时用到的三个纵坐标,而且每个半段的积分都重新计算了i2和i4用到的三个纵坐标。我们可以通过显式保存i2和i4用到的和并在命名let中传更多参数来解决这种低效率。这样有利于在integrate-segment内部和连续调用integrate-segment时共享一些信息:
(define integrate-adaptive-simpson
(lambda (f a b e)
(let* ((h (/ (- b a) 4))
(mid.a.b (+ a (* 2 h))))
(let integrate-segment ((x0 a)
(x2 mid.a.b)
(x4 b)
(y0 (f a))
(y2 (f mid.a.b))
(y4 (f b))
(h h)
(e e))
(let* ((x1 (+ x0 h))
(x3 (+ x2 h))
(y1 (f x1))
(y3 (f x3))
(i2 (* 2/3 h (+ y0 y4 (* 4.0 y2))))
(i4 (* 1/3 h (+ y0 y4 (* 4.0 (+ y1 y3))
(* 2.0 y2)))))
(if (<= (abs (- i2 i4)) e)
i4
(let ((h (/ h 2)) (e (/ e 2)))
(+ (integrate-segment
x0 x1 x2 y0 y1 y2 h e)
(integrate-segment
x2 x3 x4 y2 y3 y4 h e)))))))))
integrate-segment现在显式地设置了四个h大小的区间,五个纵坐标y0,y1,y2,y3,y4。积分i4用到了所有的坐标值,i2的区间大小是两倍的h,故只用到了y0,y2,y4。很容易看出i2和i4用到的和符合辛普森公式中的和。
比较下面对积分 $\int_{0}^{20}e^{x}dx$ 的近似:
(integrate-simpson exp 0 20 10)
(integrate-simpson exp 0 20 20)
(integrate-simpson exp 0 20 40)
(integrate-adaptive-simpson exp 0 20 .001)
(- (exp 20) 1)
可以分析出最后一个是正确的答案。看看你能不能找到一个最小的n(如果设得太小会算得超级慢。。。)让(integrate-simpson exp 0 20 n)返回一个和integrate-adaptive-simpson算出的差不多的答案?
辛普森积分法不能直接用来计算广义积分(这种积分的被积函数在某个点的值无穷大或者积分区间的端点无穷大)。然而这个积分法仍然可以用于部分积分,而剩下的部分用其他办法来获得近似值。比如,考虑伽玛函数 $\Gamma$ 。对n>0, $\Gamma(n)$ 被定义为下面的积分(积分上限为无穷):
$$\Gamma(n)=\int_{0}^{\infty} x^{n-1}e^{-x}dx$$
从上式可以看出两个结论:
这就意味着如果我们知道 $\Gamma$ 在区间(1,2)上的值,我们就可以知道任何n>0的 $\Gamma(n)$ 。实际上,如果我们放宽条件n>0,我们可以用结论b来把 $\Gamma(n)$ 扩展到 n≤0 ,而函数在 n≤0 时会发散。5
我们首先实现一个Scheme过程gamma-1-to-2,其参数n在区间(1,2)内。gamma-1-to-2的第二个参数e是精确度。
(define gamma-1-to-2
(lambda (n e)
(unless (< 1 n 2)
(error 'gamma-1-to-2 "argument outside (1, 2)"))
;...
我们引入一个局部变量gamma-integrand来保存 $\Gamma$ 中的被积函数 $g(x)=x^{n-1}e^x$ :
;...
(let ((gamma-integrand
(let ((n-1 (- n 1)))
(lambda (x)
(* (expt x n-1)
(exp (- x))))))
;...
我们现在需要让g(x)从0积分到 $\infty$ ,首先我们没法定义一个“无穷”的区间表示;因此我们用辛普森公式只积分一个部分,如 $[0,x_c]$ (c的意思是截取(cut)),对于剩下的部位,“尾部”,区间 $[x_c,\infty]$ ,我们用一个“尾部”被积函数t(x)来近似g(x),这样更加容易分析和处理。事实上,可以很容易看出对于足够大的 $x_c$ ,我们可以把g(x)替换为一个递减的指数函数 $t(x)=y_ce^{-(x-x_c)}$ ,其中 $y_c=g(x_c)$ ,因此:
$$\int_0^{\infty}g(x)dx \approx \int_0^{x_c}g(x)dx + \int_{x_c}^{\infty}t(x)dx$$
前一个积分可以用辛普森公式来解出,后一个就是 $y_c$ 。为了找 $x_c$ ,我们从一个比较小的值(如4)开始,然后通过每次扩大一倍来改进积分结果,直到在 $2x_c$ 处的纵坐标(即 $g(2x_c)$ )在一个特定的由“尾部”的被积函数纵坐标误差之内。对于辛普森积分和尾部的积分计算,我们都需要误差为e/100,就是比e再小两个数量级,这样对总体的误差不会有太大影响:
;...
(e/100 (/ e 100)))
(let loop ((xc 4) (yc (gamma-integrand 4)))
(let* ((tail-integrand
(lambda (x)
(* yc (exp (- (- x xc))))))
(x1 (* 2 xc))
(y1 (gamma-integrand x1))
(y1-estimated (tail-integrand x1)))
(if (<= (abs (- y1 y1-estimated)) e/100)
(+ (integrate-adaptive-simpson
gamma-integrand
0 xc e/100)
yc)
(loop x1 y1)))))))
我们现在可以写一个更通用的过程gamma来返回任意n对应的 $\Gamma(n)$ :
(define gamma
(lambda (n e)
(cond ((< n 1) (/ (gamma (+ n 1) e) n))
((= n 1) 1)
((< 1 n 2) (gamma-1-to-2 n e))
(else (let ((n-1 (- n 1)))
(* n-1 (gamma n-1 e)))))))
我们现在来计算 $\Gamma(\frac{3}{2})$ :
(gamma 3/2 .001)
(* 1/2 (sqrt *pi*))
第二个值是理论上的正确答案。(这是由于 $\Gamma(\frac{3}{2})=\frac{1}{2}\Gamma(\frac{1}{2})$ ,而可以证明 $\Gamma(\frac{1}{2})$ 的值是 $\pi^{\frac{1}{2}}$ )你可以通过更改过程gamma的第二个参数(误差)让结果达到任何你想要的近似程度。
[1]. 想了解为什么这种近似是合理的,请参考任意一种基础的微积分教程。
[2]. $\phi$ 是服从正态或高斯分布的随机变量的概率密度函数。其均值为0而方差为1。定积分 $\int_0^z\phi(x)dx $ 是该随机变量在0到z之间取值的概率。然而你并不需要了解这么多也可以理解这个例子!
[3]. 如果Scheme没有atan过程,我们可以用我们的数值积分过程来得到积分 $\int_0^1(1+x^2)^{-1}dx$ 的值,即 $\pi/4$。
[4]. 把常量——如phi中的 (/ 1 (sqrt (* 2 *pi*)))——提取到被积分函数外面,可以加速integrate-simpson中纵坐标的计算。
[5]. 对大于0的实数n来说$\Gamma(n)$是“减小后阶乘”函数(把正整数n映射到(n-1)!)的一个扩展。